🏋🏽 how to train your model
bigger the model, bigger the gains

It is not often that one comes across something that questions the fundamental tenets of machine learning. In this blog, I want to discuss the phenomenon of “double descent”. This questions the fundamental relationship between model complexity and prediction error (specifically, the test error) and what it means for training machine learning models.
I first came across double descent in Dr. Ben Recht’s blog post on overfitting. He argues that the conventional bias-variance tradeoff (see figure 1-a) does not make much sense, especially in the age of large neural network models, and we should embrace “complex” models. In his own words,
The advice people draw from the bias-variance boogeyman is downright harmful. Models with lots of parameters can be good, even for tabular data. Boosting works, folks! Big neural nets generalize well. Don’t tell people that you need fewer parameters than data points. Don’t tell people that there is some spooky model complexity lurking around every corner.
Also, in case you are not following his sub stack, you should! I have been following his work for the last five years and couldn’t recommend it more. His posts on Reinforcement Learning were just 🤌🏽.


In “Reconciling modern machine learning practice and the bias-variance trade-off,” Belkin et al. detail the phenomenon of double descent. This phenomenon states that if we keep increasing the model’s complexity beyond a certain point, the testing risk reduces. The figure above from their paper does a great job illustrating this. This observation goes against one of the fundamental concepts that we learn in introductory machine learning courses: a complex model does not generalize well, and we should aim to find the simplest model that explains the observed data. We learn that a simple model, or the "Occam's razor" model, is the one with the least model complexity. In this paper, they demonstrate that double descent is observed in Random Forests and Feed-Forward Neural Networks, and increasing the complexity of the model improved its generalizability as well.
Nakkiran et al., in "Deep Double Descent: Where Bigger Models and More Data Hurt," show that double descent is prevalent across multiple machine learning architectures and datasets. The recent successes of Large Language Models (LLMs) also show that larger models tend to generalize quite well. These works suggest that we should not be afraid of over-parameterization.
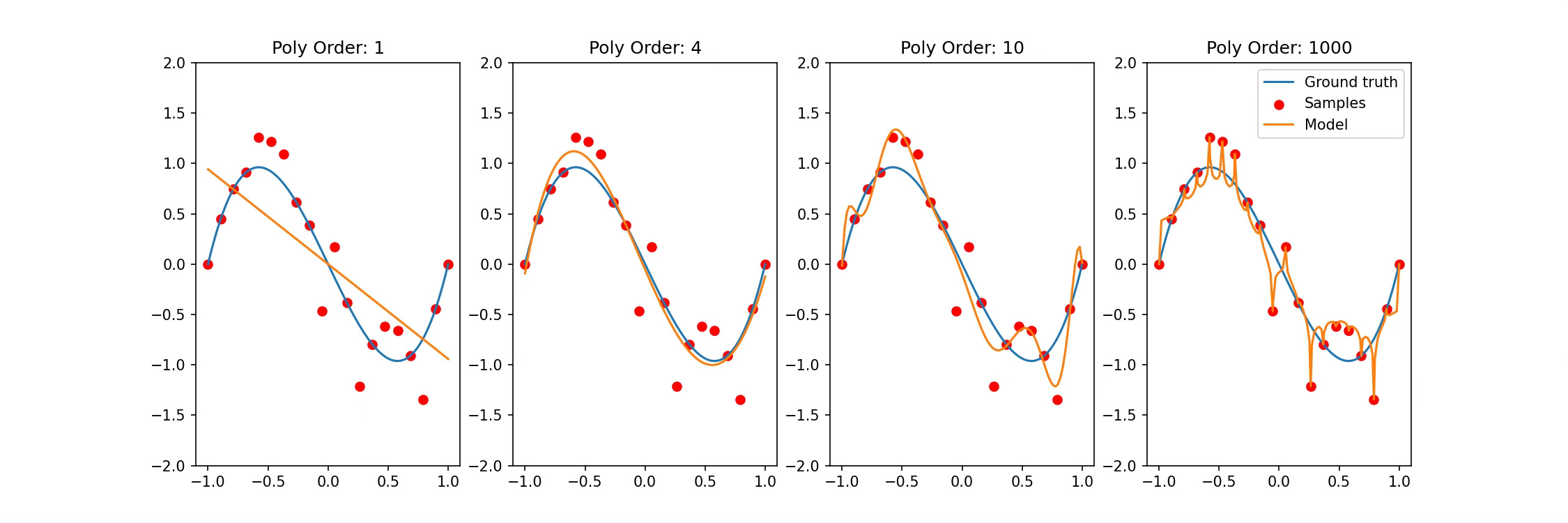
Consider a simple problem of polynomial fit. We learn that by increasing the order of the polynomial beyond a certain point, our model will overfit and the testing error will increase. However, if we keep increasing the model complexity, as seen in the figure below, we notice that the fit does get better. Rather than a smooth approximation in lower-order polynomials, higher-order polynomials tend to capture the dynamics of the observed data better. The code used for generating this figure is available here.
I find it fascinating that even after all the interest and research in machine learning, there is still so much about these models that we are yet to discover.
Thanks for reading!
Proofread for grammar and typos by mistral.ai 🤖